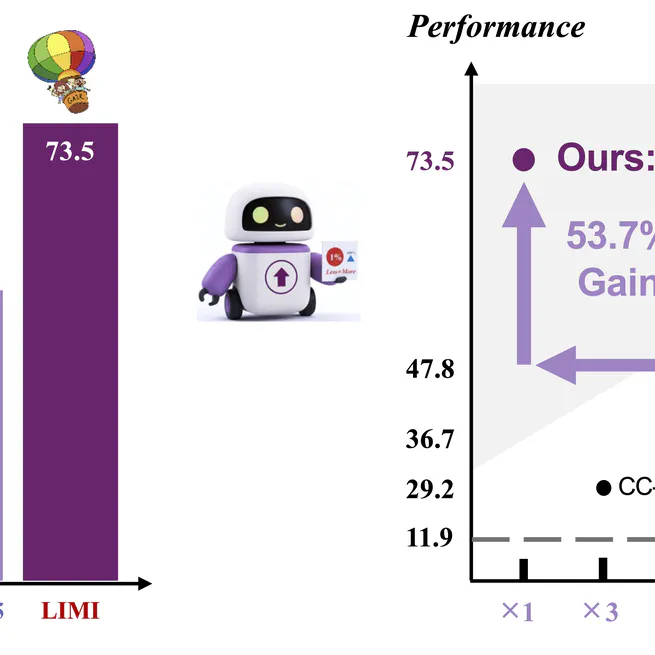
LIMI: Less is More for Agency
Less is More for Agency
Sep 25, 2025
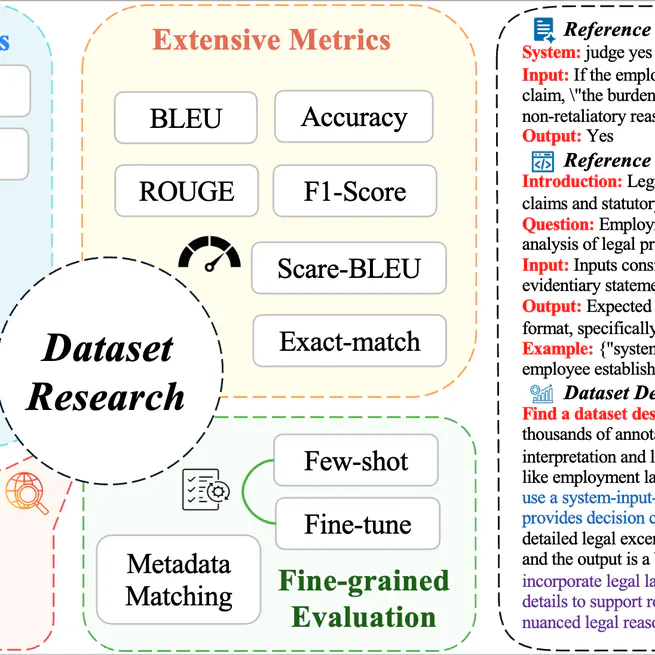
DatasetResearch: Benchmarking Agent Systems for Demand-Driven Dataset Discovery
Benchmarking Agent Systems for Demand-Driven Dataset Discovery.
Aug 10, 2025
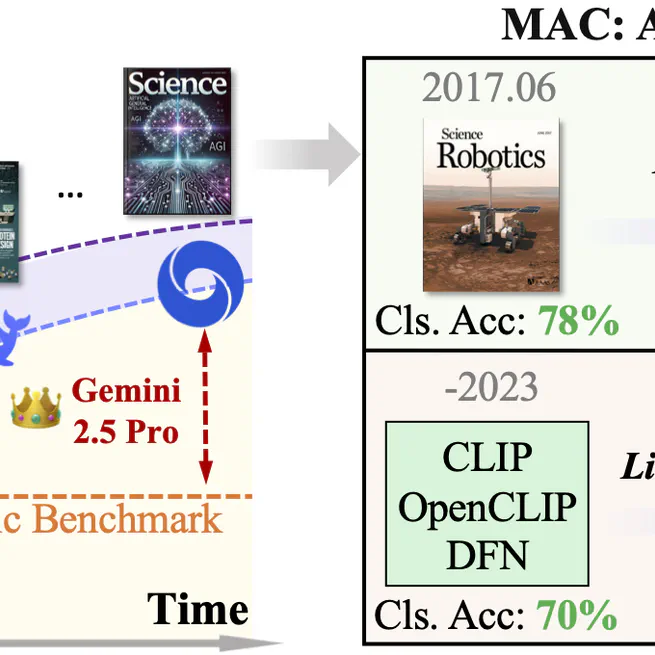
MAC: A Live Benchmark for Multimodal Large Language Models in Scientific Understanding
A live benchmark for multimodal large language models in scientific understanding.
Aug 8, 2025
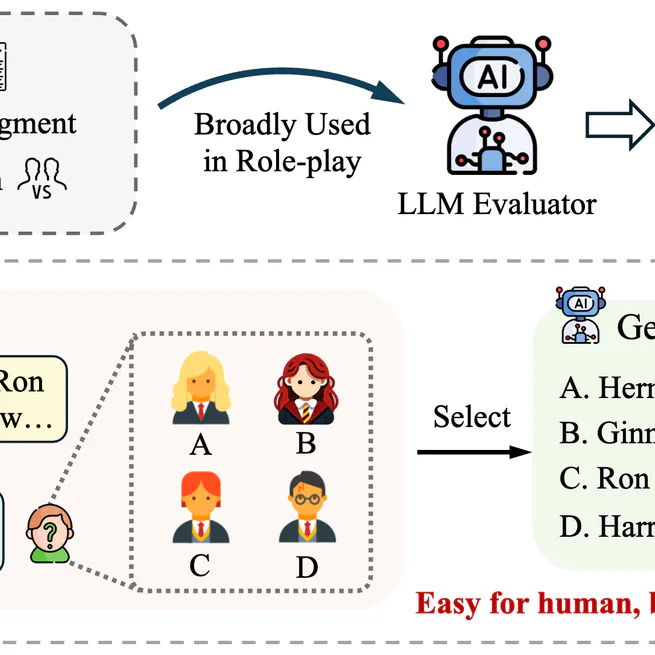
PersonaEval: Are LLM Evaluators Human Enough to Judge Role-Play?
Are LLM Evaluators Human Enough to Judge Role-Play?
Aug 6, 2025